컴퓨터사이언스 부트캠프 with 파이썬 책을 공부하며 정리한 포스팅입니다.
개인 공부후 정리용으로 남기는 포스팅으로 내용상에 오류가 있을수 있습니다.
예제 코드는 Computer-Science 를 통해 실습하고 있습니다.
핵심개념
- 스레드
- 멀티프로세스
- 멀티스레드
- 멀티스레딩
- 경쟁조건
- 상호배제
스레드
- 프로세스안의 실행 흐름의 단위로 스케줄러에 의해 CPU를 할당받을 수 있는 인스트럭션의 나열
- 실행 흐름이 하나면 단일 스레드, 그 이상이면 멀티 스레드
- 스레드 제어 블록(TCB, Thred Control Block)을 갖는다
- 프로세스의 프로세스 제어 블록(PCB, Process Control Block)과 매우 유사함
- 스레드와 프로세스의 차이점을 알기 위해선 멀티 프로세스와 멀티 스레드를 비교해야함
멀티프로세스와 멀티스레드
- 단일 코어 CPU에서 여러 개의 실행흐름이 동시에 필요하다고 가정하면 실행 흐름 사이에서 데이터 공유 필요
- 실행 흐름 = CPU를 점유하고 인스트럭션을 실행하는 것을 뜻한다.
- 따라서 여러 실행 흐름을 구현하려면 멀티프로세스나 멀티스레드로 구현해야함
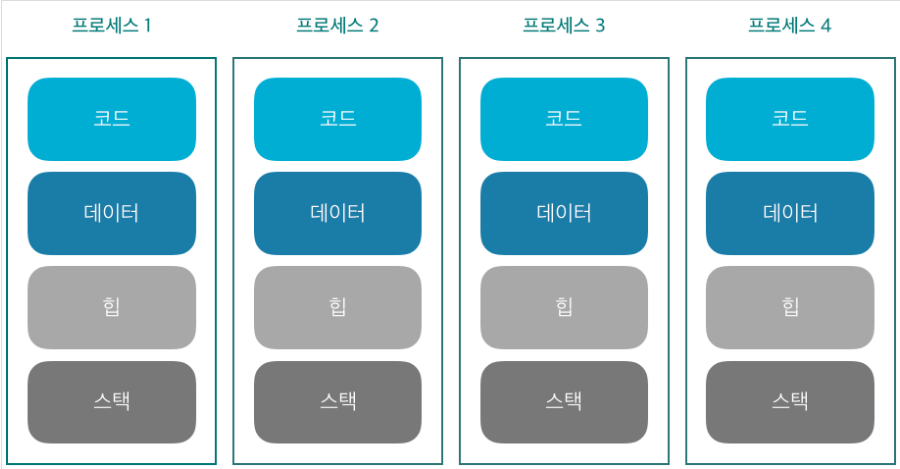
멀티프로세스의 메모리 구조
- 그림에서와 같이 프로세스는 서로 독립적인 메모리 공간을 가지므로 기본적으로 데이터를 공유할수가 없다
- 데이터를 공유하려면 특별한 기법을 사용해야함
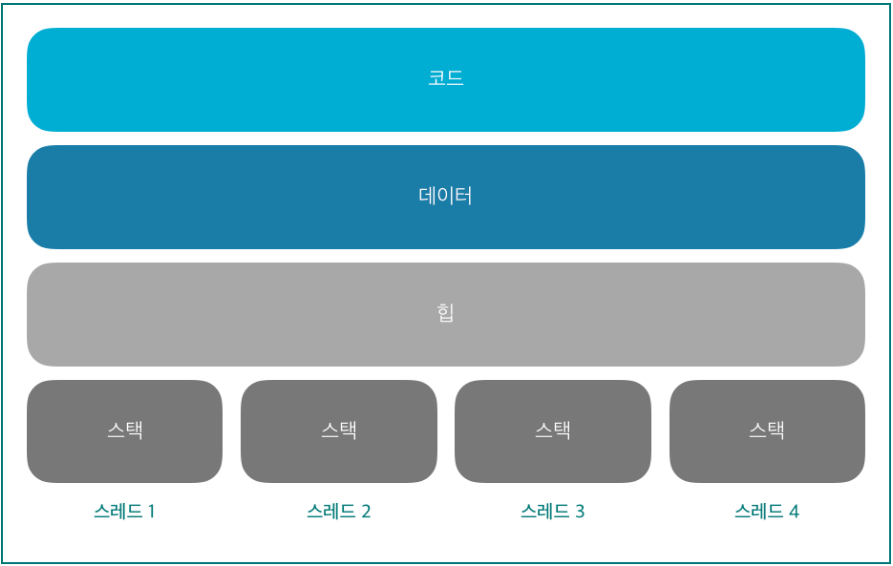
멀티스레드의 메모리 구조
- 멀티스레드로 구현하면 데이터를 쉽게 공유할수 있다.
- 여러 스레드가 스택만 서로 다른 공간을 갖고 코드, 데이터, 힙은 공유하기 때문이다.
- 이처럼 여러 실행 흐름이 동시에 필요한 프로그래밍을 동시성(concurrency) 프로그래밍이라 하고
- 이를 구현하고자 멀티스레딩을 이용한다.
멀티스레딩 구현
>>> li = [i for i in range(1001)]
>>> for idx in range(1001):
li[idx] *= 2
- 0부터 1000까지 정수가 담긴 리스트에서 모든 요소의 값을 두 배로 만들고자 한다.
코드예시
import threading #1
# 스레드에서 실행할 함수
def thread_main(li, i): #2
# range() 안의 값이
# 스레드가 담당할 리스트의 인덱스 범위를 결정
for i in range(offset * i, offset *(i + 1)): #3
# 요소에 2를 곱한다
li[i] *= 2
num_elem = 1000 # 리스트 요소 개수
num_thread = 4 # 스레드 개수
# 오프셋 = 리스트 요소 개수 // 스레드 개수
# 스레드 함수에서 연산을 담당한 인덱스 범위를 구하는 데 쓰인다
offset = num_elem // num_thread
li = [i+1 for i in range(num_elem)]
# 스레드를 담을 리스트
threads = [] #4
for i in range(num_thread): #5
th = threading.Thread(target = thread_main, args = (li, i)) #6
threads.append(th)
for th in threads:
# 스레드 실행 시작
th.start() #7
for th in threads:
# 스레드 실행 완료 대기
th.join() #8
print(li)
# 실행결과
[2, 4, 6, 8, 10, 12, ...]
- #1 - threading 모듈은 멀티스레딩을 구현하는데 필요
- #2 - thread_main() 함수는 4개의 스레드에서 실행할 함수. 인자가 리스트 li와 정수 i
- 정수 i는 리스트에서 요소의 인덱스 범위를 결정하는데 사용
- #3 - for 문으로 인덱스 범위를 설정해 순회하면서 각 인덱스 요소에 2를 곱한다.
- #4 - threads 리스트에는 생성된 스레드를 저장
- #5 - for 문으로 스레드를 4개 생성한다
- #6 - Thread 객체 th를 생성
- target은 스레드에서 실행할 함수, args는 함수에 전달할 인자
경쟁조건(race condition)
-
스레드 여러 개가 공유 자원에 동시에 접근하는 것
-
공유자원 : 여러 스레드가 동시에 접근,수정,공유 가능한 자원
코드예시
import threading
# 모든 스레드가 공유할 데이터
g_count = 0 # 1
# 스레드가 실행할 함수
def thread_main(): # 2
global g_count
for i in range(100000):
g_count += 1
threads = []
for i in range(50): # 3
th = threading.Thread(target = thread_main)
threads.append(th)
for th in threads:
th.start()
for th in threads:
th.join()
print('g_count : {:,}'.format(g_count)) # 4
# 실행결과 1
g_count : 3,339,313
# 실행결과 2
g_count : 3,838,022
# 실행결과 3
g_count : 3,533,168
#1- 전역 변수g_count를 선언 <- 공유자원#2-thread_main()함수 안에서 g_count 값에 1을 100,000번 더한다#3- for문으로 스레드를 총 50개 만듦
g_count의 최종 값은 스레드가 각 100,000번씩 증가시키므로 5,000,000이 기대되지만 실행결과는 매번 달라진다.
이상적인 경우에서는 먼저 전역 변수 g_count 값을 범용 레지스터로 가져와 값을 증가시키고, 연산이 끝난 레지스터 값을 g_count에 저장한다.
이제 컨텍스트 스위칭이 일어나 스레드 2에 CPU가 할당된다.
이 과정이 반복되는 것이 이상적인 경우이지만 선점형 스케줄링에서는 스레드 1의 연산이 완전히 끝날 때까지 컨텍스트 스위칭을 기다려 주지 않는다.
g_count에 값을 저장하기 전에 컨텍스트 스위칭이 일어나면 다른 스레드가 이전 레지스터 값을 복원하고 이전 상태에 이어 연산을 마무리한다.
각 스레드의 관점에서 보면 스레드는 첫 번째 경우나 두 번째 경우 모두 g_count 값에 1을 더하는 같은 연산을 하지만 컨텍스트 스위칭이 언제 일어나는지에 따라 전혀 다른 결과가 나온다.
스레드가 공유 자원에 단순히 접근만 하고 값을 변경하지 않으면 아무런 문제도 발생하지 않지만
값을 변경하려고 하면 문제가 발생하는데 이를 임계영역(critical section)이라고 한다
상호배제(mutual exclusion)
- 경쟁 조건 문제를 해결하기 위해서 사용하는 방법.
- 원리 : 스레드 하나가 공유 자원을 이용하는 동안에는 다른 스레드가 접근하지 못하게 막는 것.
코드예시
import threading
# 모든 스레드가 공유할 데이터
g_count = 0
# 스레드가 실행할 함수
def thread_main():
global g_count
# Lock을 획득
# 한 스레드가 획득하면
# 획득을 시도한 나머지 스레드는 대기
lock.acquire() #2
for i in range(100000):
g_count += 1
# Lock을 반환
# 획득했던 스레드가 반환하면
# 대기하던 스레드 중 하나가 획득
lock.release() #3
# Lock 객체 생성
lock = threading.Lock() #1
threads = []
for i in range(50):
th = threading.Thread(target = thread_main)
threads.append(th)
for th in threads:
th.start()
for th in threads:
th.join()
print('g_count : {:,}'.format(g_count)) # 4
# 실행결과
g_count: 5,000,000
-
경쟁 조건의 코드예시와 비교해보면
#1~#3까지 세 줄만 추가 #1- Lock 객체 생성#2- 임계 영역이 시작되는 곳에서 lock의 acquire() 메서드를 호출acquire()메서드는 Lock객체를 ‘획득’- 한 스레드가 획득한 다음에는
acquire()메서드를 호출해도 다른 스레드는 대기 상태에 있다.
#3- Lock객체를 획득했던 스레드가 임계영역을 빠져나와release()메서드 호출release()메서드는 Lock 객체를 ‘반환’
Comments